At my previous job, we were told not to use partials to clean up our view code, because each rendering of a partial would add around 10ms to the overall response time. After I was told this I did a quick test in my dev environment, but I’d never actually tested the claim on production … until today!
The setup
I created a new rails project and generated a scaffold I called things. On the index page, underneath the auto-generated table, I put the following:
<% if params[:manypartials].present? %> <p>Many partials:</p> <% 1000.times do %> <%= render "simplepartial", iterations: 1 %> <% end %><% else %> <p>One big partial:</p> <%= render "simplepartial", iterations: 1000 %><% end %>
I then created the partial simplepartial and added this code:
<% iterations.times do %> <p>This is a simple partial. Hello from the partial!</p><% end %>
Results
I launched the dev server with rails s and the production server with rails s -e production. I ran
time curl "http://0.0.0.0:3000/things?manypartials=true" > /dev/null
and
time curl "http://0.0.0.0:3000/things" > /dev/null
to make the requests. (The pipe to /dev/null is to reduce the time spent printing stuff to the terminal.)
Many partials
One big partial
Dev
44.365s
0.852s
Production
0.273s
0.152s
So it seems that rendering 1000 partials will cause around 100–200ms of extra rendering time. That’s certainly not great, but it may not be too high a price to pay for HTML templates not growing to thousands of lines.
When programming on low-resolution screens,
I like to use 10pt Monaco with antialiasing turned off.
But when switching to my MacBook’s retina display,
I want antialiasing turned back on.
Until now, I would manually comment/uncomment some CSS
in Atom’s styles.less file to change this.
Turns out, you can define
CSS rules based on the current screen resolution.
By adding the following to styles.less,
Atom automatically switches the font and antialiasing settings
as soon as you move the window from one screen to the other:
I’m currently trying out Atom as the main tool for my computer job and I wanted to make it more fun, so I added some CSS to make the cursor move smoothly and give the text-selection rounded corners. To try it yourself, click on Stylesheet in the Atom menu and paste this code:
atom-text-editor .cursor { transition: all 80ms;}atom-text-editor .selection { border-radius: 4px; transition: all 20ms;}
Having numbers and letters in the same text is a difficult challenge for typography:
Arabic numerals have a completely different origin, and thus completely different shapes than roman letters.
If you just somehow throw them in the middle of your text, the numbers will look out of place.
But (let’s pretend) you want them to look like they fit in.
You don’t want your numbers to show up at their friend’s party and someone walks up to you them and is like, “So how do you know the host?”, and you’re the numbers are like, “I study physics with them,” “We come from the other end of the world,” and the person is like, “Haha yeah, I figured, from the way you look.”
Because that would be embarrassing.
So the typography friends all sat down together and adapted numbers to look more like letters.
Since there are two kinds of letters, they made two kinds of numbers.
One kind to go well with upper case letters, for titles and tables, and one to go well with lower case letters, for body text.
They are called by many names, but we’ll call them upper case and lower case numbers.
Using upper case numbers in the middle of body text has the same effect as using ALL CAPS in the middle of body text: it makes the number seem damn important. That’s fine if the number is damn important, but most numbers are not.
During most of the nineteenth and twentieth centuries, lining figures were more widely known as ‘modern’ and text figures as ‘old-style.’ Modernism was preached as a sacred duty, and numbers, in a sense, were actually deified. Modernism is nothing if not complex, but its gospel was radical simplicity. Many efforts were made to reduce the Latin alphabet back to a single case. (The telegraph and teletype, with their unicameral alphabets, are also products of that time.) These efforts failed to make much headway where letters were concerned. With numbers, the campaign had considerable success. Typewriters soon came to have letters in both upper and lower case but numbers in upper case alone. And from typewriters come computer keyboards.
Typographic civilization seems, nonetheless, determined to proceed. Text figures are again a normal part of type design – and have thus been retroactively supplied for faces that were earlier denied them. However common it may be, the use of titling figures in running text is illiterate: it spurns the truth of letters.
Ok, let’s continue.
Unfortunately, uppercase numbers aren’t always bad. Especially the scientifically minded will often wish to have big tables of numbers, and the contents of tables are supposed to look nice and regular – “tabular”, you might say. In this case, it makes sense to take advantage of the uniform, blocky shapes of upper case numbers to make everything line up neatly. As a result, we’d want lower case numbers for text, and upper case numbers for tables.
Buuuuuuut, because fonts and the web and everything are complicated and we can be glad to even occasionally get half-decent fonts on the web at all, this is too much to ask. Instead, let’s see if we can find a middle ground where everyone is only sorta unhappy.
The solution – read this part
From what we’ve learned in the last section, if you ever want to have a table with numbers in your text, using lowercase numbers is kind of a nonstarter. Instead, we’re aiming for uppercase numbers that are less awful.
Let’s look at some fonts:
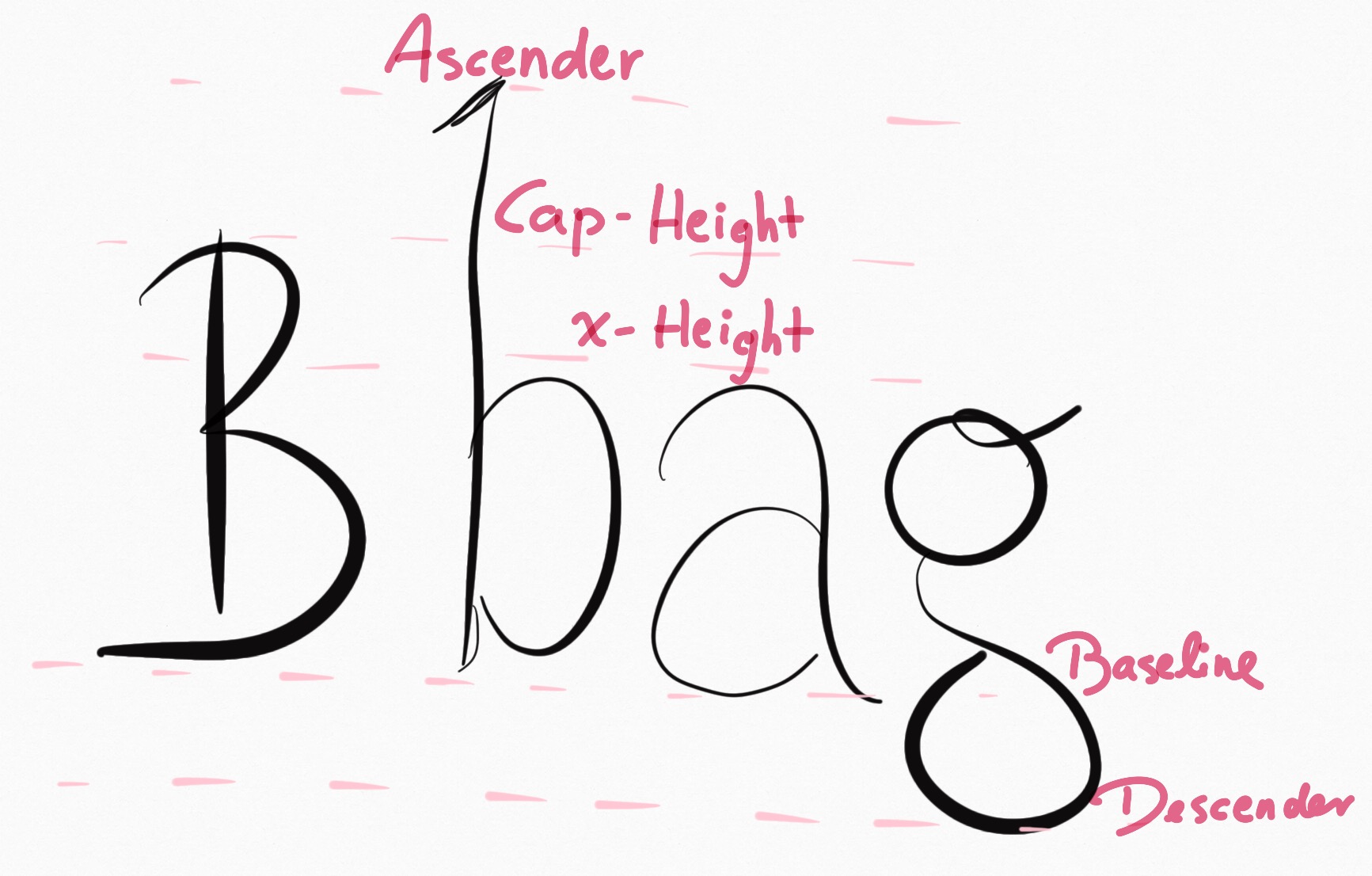
A number and a typo. From top to bottom: Times, EB Garamond, Palatino, Hoefler Text, Gentium Book.
{:.right.half}
In the first and third line (Times New Roman, Palatino), the problem is clearly visible: the numbers are absolutely gigantic and distract from the text. In the second and fourth line (EB Garamond, Hoefler Text), lowercase numbers emulate the dynamics of the text and thus blend in better. In the fifth line (Gentium Book), the numbers are upper case and thus usable for tables and titles, but they aren’t obnoxiously huge. Now, the makers of Gentium did not just scale down the numbers and call it a day. Instead, they lowered the entire cap height (see picture on the right or possibly above). This is especially visible in the “The” at the beginning of the line; the “T” is much shorter than the “h”. As a result, lowercase letters can retain their ascender height and don’t look squished, and numbers (which have cap-height) aren’t obnoxious. On top of that, you get the positive side effect of having nice-looking acronyms without needing small-caps, which has been another source of constant frustration for me.
I first saw this technique in the font FiveThirtyEight use:
By the nature of their content, they need a lot of numbers and acronyms, while still wanting to maintain a generally nice-looking page. Their font solves this problem wonderfully.
In conclusion: If you want good looking text and not worry about things and not bother with small numbers, find a font with a small cap-height and/or large x-height, and ideally with long-enough ascenders that it doesn’t look all cheap and squished. If you’re unsure, just use Gentium Book – that one’s in Google Docs, looks cool, and has all kinds of non-latin accents and stuff too.
I noticed I wasn’t happy with the way I spend my time. Over the last year or so I learned to structure my work habits such that I need the least amount of willpower possible to get myself to work. I tried hard to get myself to do things without requiring willpower and, in the process, built somewhat of an aversion to do anything that seemed like it might require effort. For the most part, this was good: I learned to notice moments when I just didn’t have the mental capacity to do work, and so learned not to judge myself for sometimes not working and instead looking at comics on the internet.
On the flip-side, I have become dissatisfied with the amount of challenging activities I do in my non-work time. Too often, I spend my after-work time doing only effortless things, neglecting my desire to do low-but-finite-effort activities like reading, writing1, or even just tidying up the apartment for a few minutes.
It’s not that I never do anything useful with my time, but I feel like I could increase the quality-density of my time by making more of an effort. Additionally, maybe spending a bit of willpower will allow me to build a habit of taking fewer (or shorter) breaks and, generally, living (at least somewhat) faster.
The experiment
So I decided to do an experiment: For one day, I spend as much willpower as I can to combat my usual slowness and aversion to effortful tasks. On the object level, this meant roughly three things:
When I’m taking time to relax, instead of watching cat videos, I’ll read things, take notes, etc.
Whenever I’m feeling like I just want to take a break and not do anything, I’ll go against that urge and work anyway. The reasoning behind this is that, if it turns out I can’t focus in the moment, I can still stop working. But at least I don’t run the risk of underestimating my ability to work.
I resist the urge to put tasks off if I can easily do them immediately.
The result
Overall, the results of this experiment are surprisingly unspectacular.
Getting up in the morning wasn’t a problem since I had an early call that I was looking forward to. After that, I tried, just for fun, to step into the shower before the water was at the right temperature. That worked … so … yay.
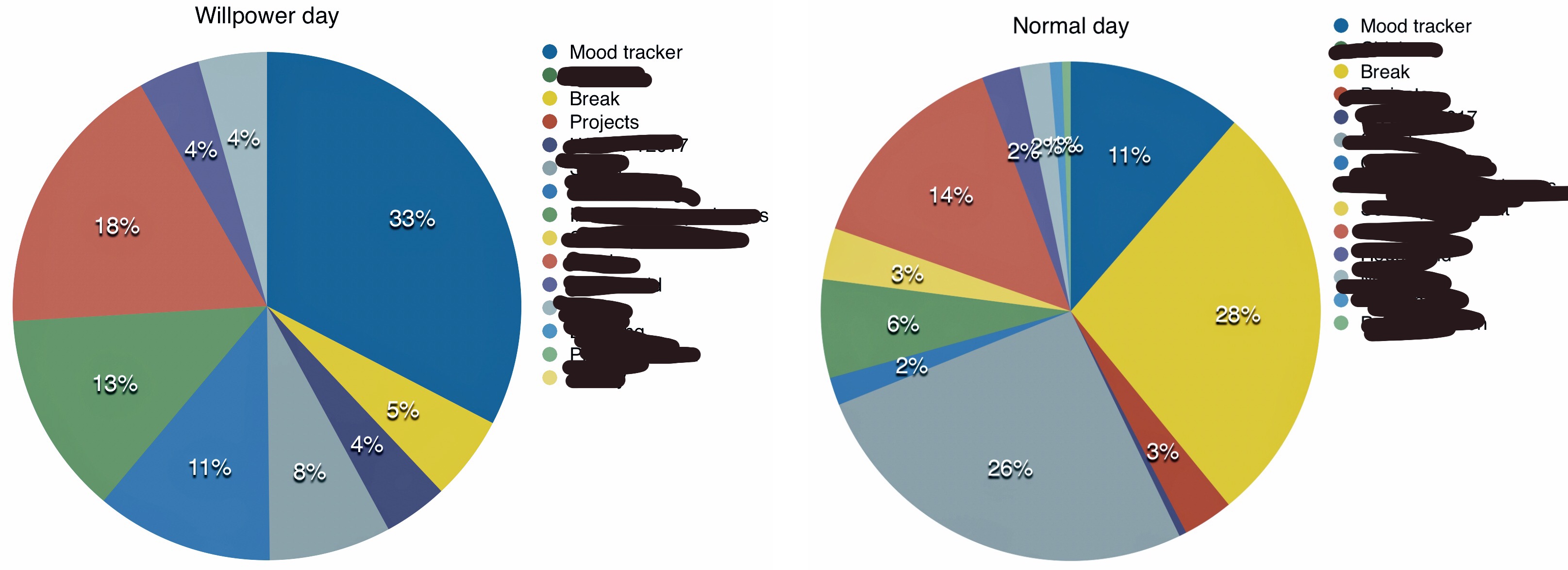
Looking at the way I spent my time during the day, it seems like noticing when I’m doing nothing, and then doing something instead, is a good idea:
Time tracking results on an average day compared to Willpower Day. Making charts from spreadsheets is really difficult.
I spent significantly more time working and less time doing “break” than on the average day.
What makes the experiment so unspectacular is that it turned out there were actually not that many situations where I could really change anything using willpower. I could will myself to go in the cold shower, sure, and I can will myself to read a bit more, but when I can’t think because my brain is all used up, there is nothing I can do about that. There are some emails I can will myself to write faster, but when I’m faced with a mental block because of anxiety or descision fatigue, what I really need is L-theanine, not more stress.
The final unsurprising finding is that I got extremely tired and needed to sleep for 10½ hours after the day, plus a 90-minute nap during the day. Wow. That’s 12 hours total! Okay, let’s start this paragraph over.
As a final finding, I was quite surprised with how much extra sleep my body required just from trying to work a little more. I already need a lot of sleep, but 12 hours is a bit more than I’m happy to accept. Two caveats to the surprise:
Since I had an early morning call I slept only 7½ hours the previous night, which is a bit less than my average.
I just today realized that there is no more caffeinated coffee in this house and I may just have been feeling strangely tired during the day because I was drinking decaf without realizing it.2
In conclusion
Using a bit more willpower seems good. Having regular designated willpower days may be good practice to get into the habit of being strong of will. Don’t overdo it though.
Footnotes
Calling writing “low-effort” is a bit of a stretch, but taking some notes shouldn’t be impossible. ↩
This is pretty cool, too, because I’ve now spent 2 or 3 days without caffeine, which means the worst of the withdrawal headaches should be gone soon and I get a caffeine-addiction-reset. ↩

 {:.right.half}
{:.right.half}